Registers of Czech journalism from 1995 to 2018
Václav Cvrček
4th March 2022
Introduction
Media discourse / journalistic style
Tendencies/hypotheses about the change since 1990s:
- less official, less formal, more spontaneous (Čmejrková 1996, 2006, 2007, 2008, Hoffmannová 1996, 2003, Hoffmannová & Müllerová 2000, Mareš 2003, 2006, 2007, Müllerová 1996, 2003, Müllerová & Hoffmannová 1997)
- “colloquialization” of journalistic discourse (Čmejrková 2008: 74; Schneiderová 2013: 105)
- “conversationalisation” of public discourse (Čmejrková 2008: 74; Schneiderová 2013: 105) – not only in tabloids (!)
- “tabloidization” of mainstream journalism (Schneiderová 2013: 100)
Testing the hypothesis
- qualitative judgments × quantitative tests
- small-scale studies × large samples
Multi-dimensional analysis
Principles of multi-dimensional analysis (MDA)
Biber 1995; Biber & Conrad 2009
- systemic & functional variability (× random,
sociolinguistic…)
- motivated by context & situation
- text production process involves interrelated choices
- dimensions of variation (“intratextual” perspective)
- model of register variation can be used for evaluation of texts
Methodology of MDA
- corpus compilation
- features: operationalization & extraction
- statistical analysis (factor analysis, FA) \(\rightarrow\) dimensions
- interpretation of results
MDA of Czech
CNC: MDA team

MDA of Czech
Mini-portal https://www.korpus.cz/mda
Cvrček, V. – Komrsková, Z. – Lukeš, D. – Poukarová, P. – Řehořková, A. – Zasina, A.J. (2021): From extra- to intratextual characteristics: Charting the space of variation in Czech through MDA. Corpus Linguistics and Linguistic Theory 17(2), p. 351-382.
Cvrček, V. – Komrsková, Z. – Lukeš, D. – Poukarová, P. – Řehořková, A. – Zasina, A. J. (2018): Variabilita češtiny: multidimenzionální analýza. Slovo a slovesnost 79, (p. 293–321).
Cvrček, V. - Laubeová, Z. - Lukeš, D. - Poukarová, P. - Řehořková, A. - Zasina, A. J. - Benko, V. (2020): Comparing web-crawled and traditional corpora. Language Resources & Evaluation 54, p. 713–745.
Cvrček, V. – Laubeová, Z. – Lukeš, D. – Poukarová, P. – Řehořková, A. – Zasina, A. J. (2020): Registry v češtině. Praha: Nakladatelství Lidové noviny, (233 p.).
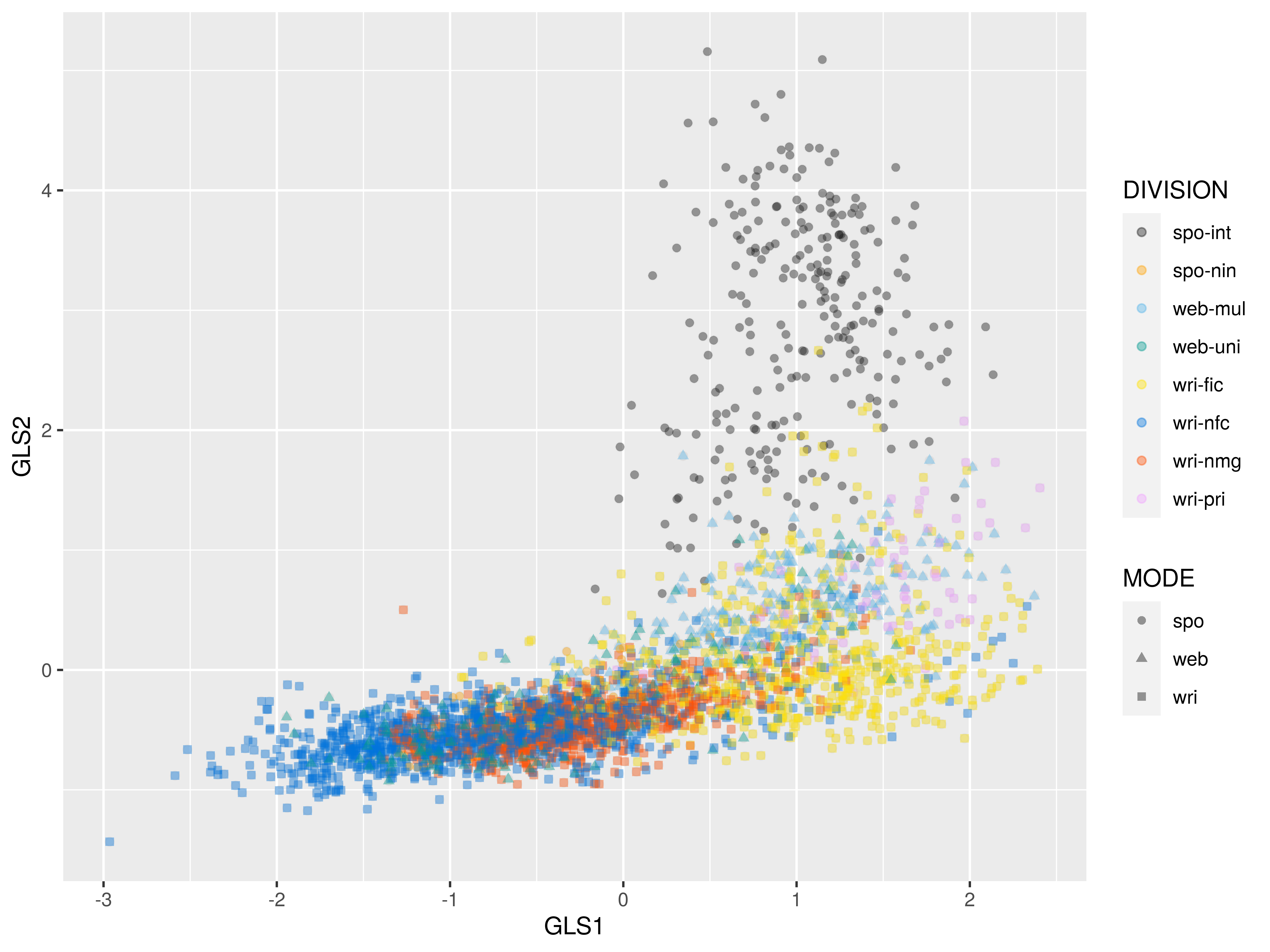
Data: Koditex corpus
- “traditional” carefully designed corpus covering all available text types
- guiding principles: diverse, contemporary, text
length control
- text excerpts = chunks (not whole texts)
- 3 modes –
wri,spo,web- 8 divisions, 45 classes, \(\approx\) 200,000 words per class
| Category | # |
|---|---|
| Tokens | 10,8 M |
| Words (excl. punct.) | 9 M |
| Lemmata (types) | 204 K |
| Text chunks | 3 334 |
Koditex: composition

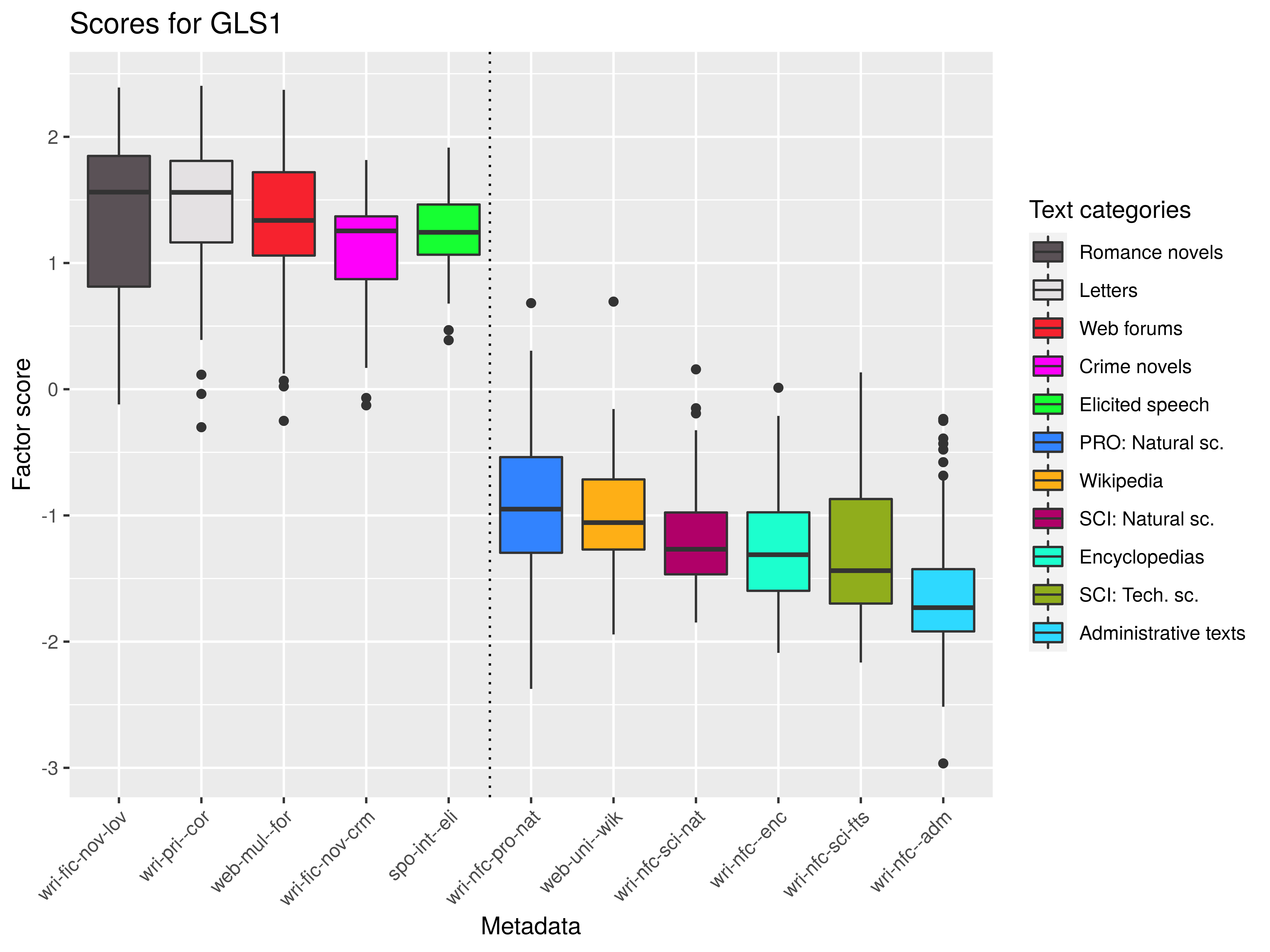
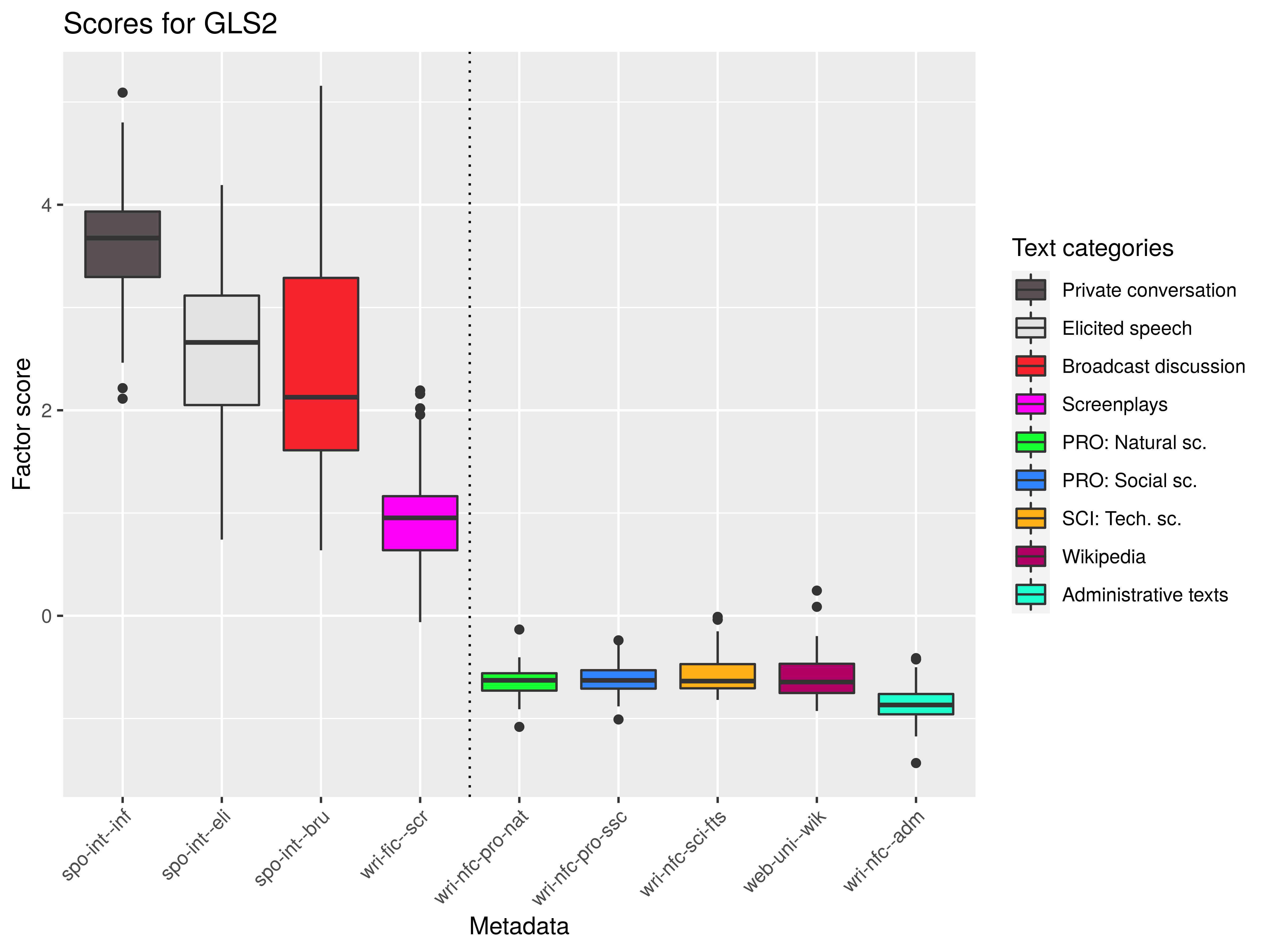
Features and their operationalization
Originally 140+ features, final list 122, e.g.:
- phonetics – narrowing é > í, vowel breaking ý > ej, average word length…
- morphology – freq. of cases, numbers, moods, tenses…
- derivation – adjectives denoting similarity, verbal nouns, diminutives…
- lexicon – indefinite pronouns, reporting verbs, verbs of thinking, semantically bleached nouns…
- pragmatics – contact expressions, fillers, intensifiers, downtoners…
- syntax – types of attributes, clusters of POS, types of dependent clauses…
- text/discourse – questions, phraseology, word repetition…
Statistical evaluation: Factor analysis
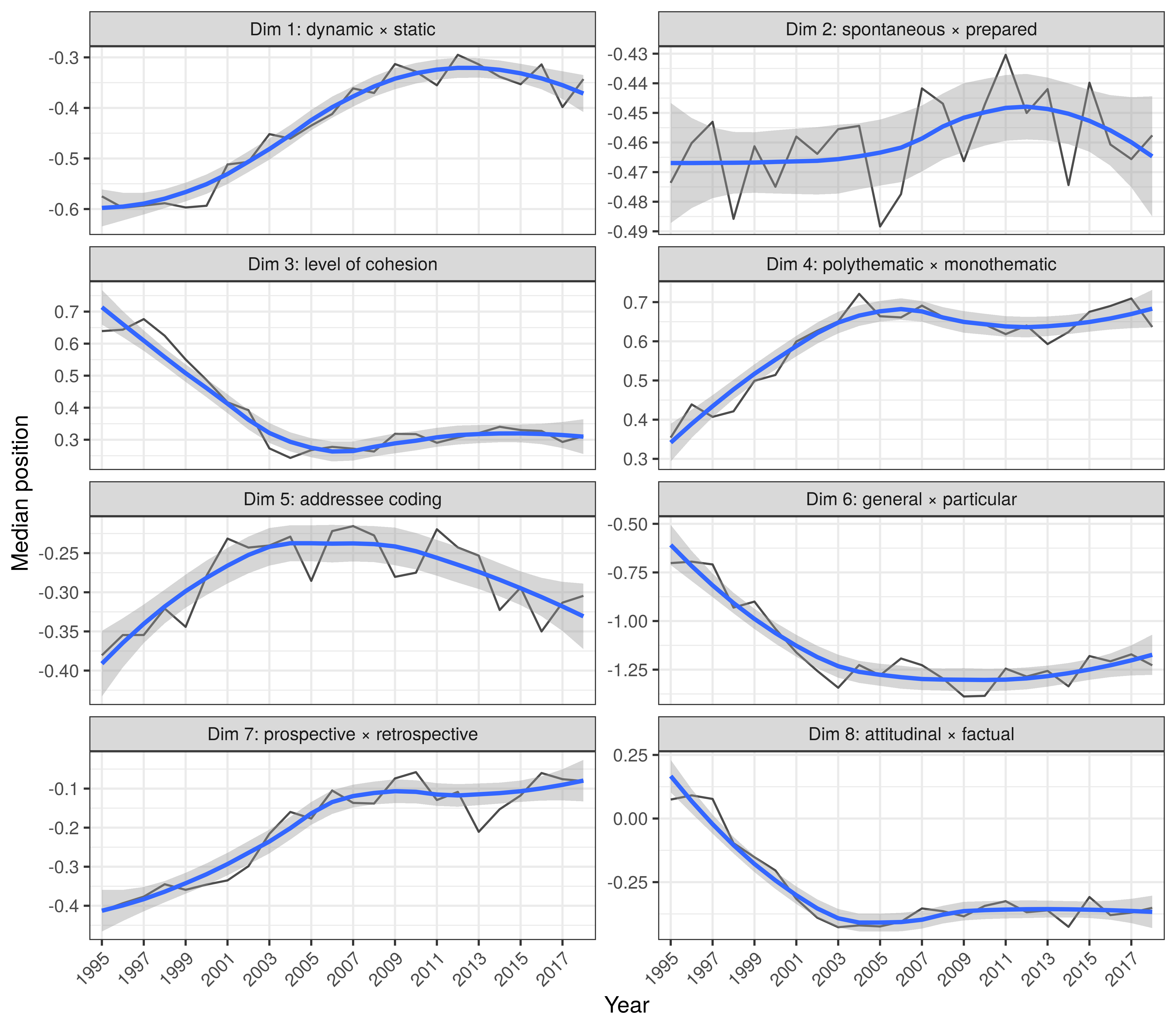
Interpretation: Dimensions of variability
- dynamic (+) × static (-): verbal/clausal × nominal/phrasal constructions
- spontaneous (+) × prepared (-): hit-and-miss redundant coding × carefully worded formulations
- higher (+) × lower (-) level of cohesion: propensity to use connecting devices and means of intratextual reference
- polythematic (+) × monothematic (-): lexically rich × repetitive texts
- higher (+) × lower (-) amount of addressee coding: explicit references to communication partners
- general (+) × particular (-): description of general qualities × discussion of particular referents
- prospective (+) × retrospective (-): present and future tense, non-narrative × past tense, narrative
- attitudinal (+) × factual (-): degree of explicit epistemic certainty, higher × lower amount of hedging
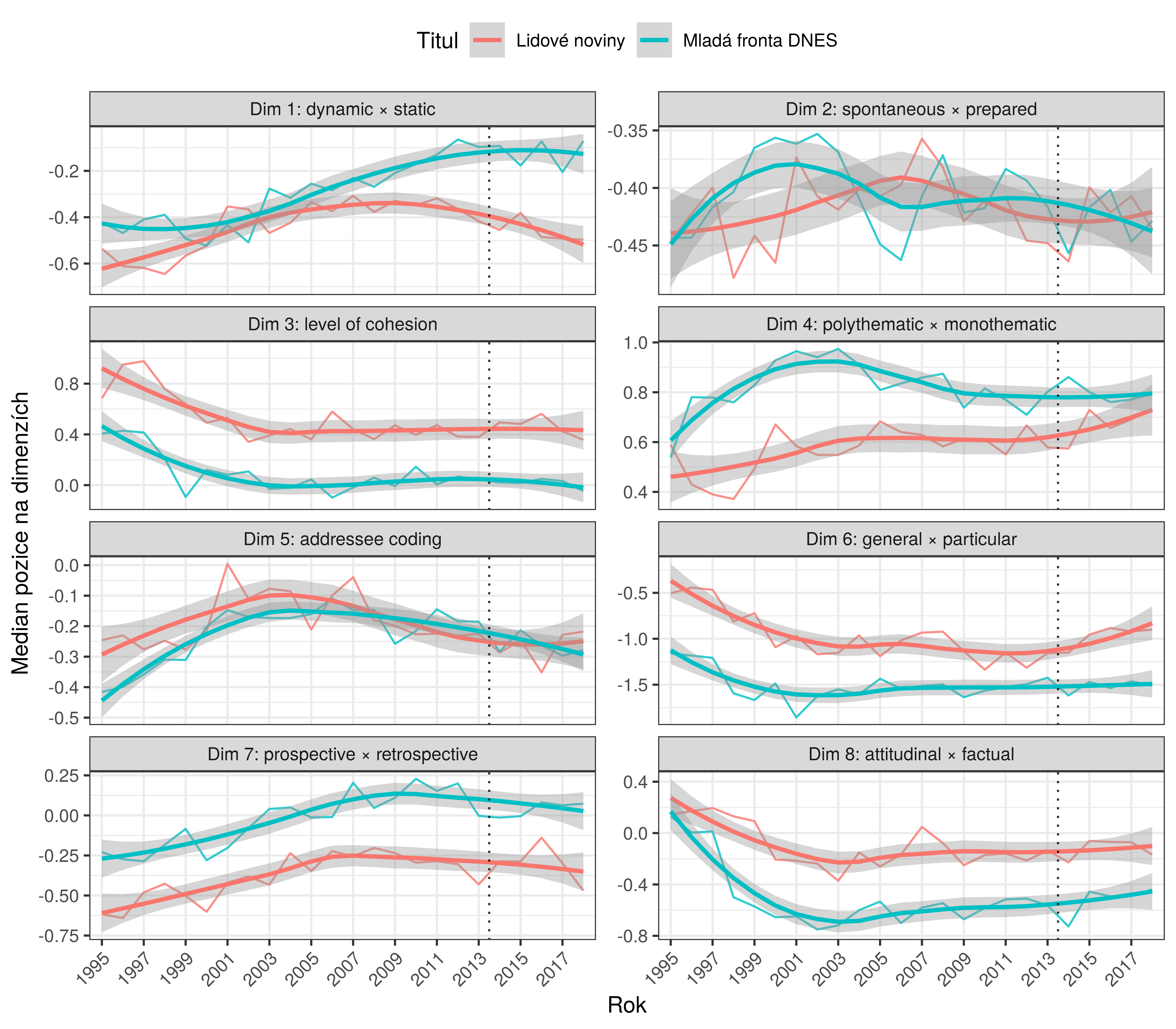
Dim 1: dynamic (+) × static (-)
Dim 2: spontaneous (+) × prepared (-)
2D-plot: dim 1 and dim 2
Sampling the data
Journalistic texts in the sample
- 2 random samples from SYNv8 – identical results
- 4 major mainstream titles (Mladá fronta DNES, Lidové noviny, Právo, Hospodářské noviny) + major tabloid title (Blesk)
| Title | Texts | Tokens |
|---|---|---|
| Blesk | 4400 | 5977000 |
| Hospodářské noviny | 4800 | 7188977 |
| Lidové noviny | 4800 | 7352860 |
| Mladá fronta DNES | 4800 | 6852975 |
| Právo | 4800 | 6773351 |
- 4,800 text samples for each title (1,000–5,000 tokens)
- 34M words in total
Sample – newspapers & coverage
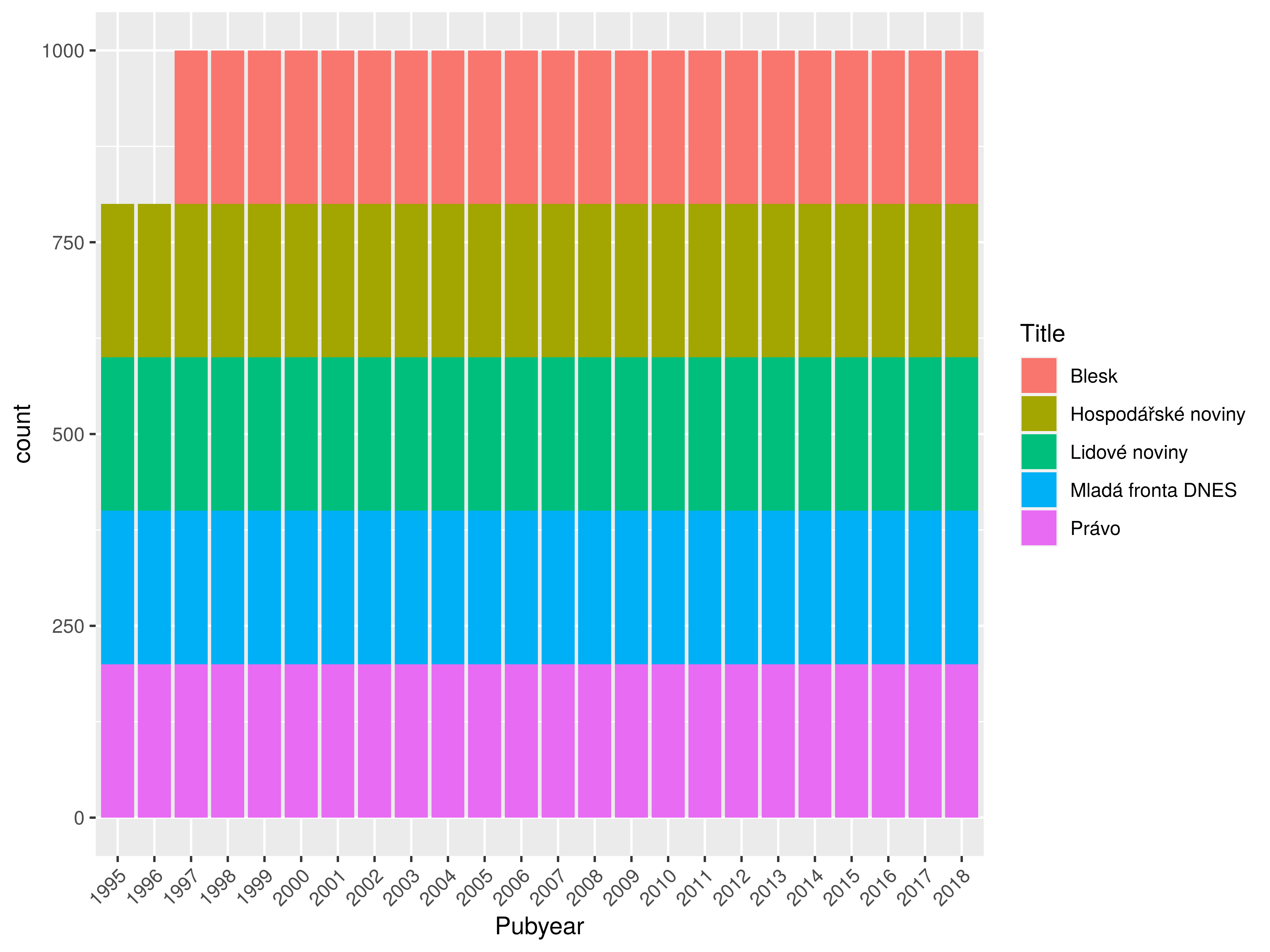
Results of projecting the data on MD model
Major tendencies of mainstream media
Dim 1: dynamic × static
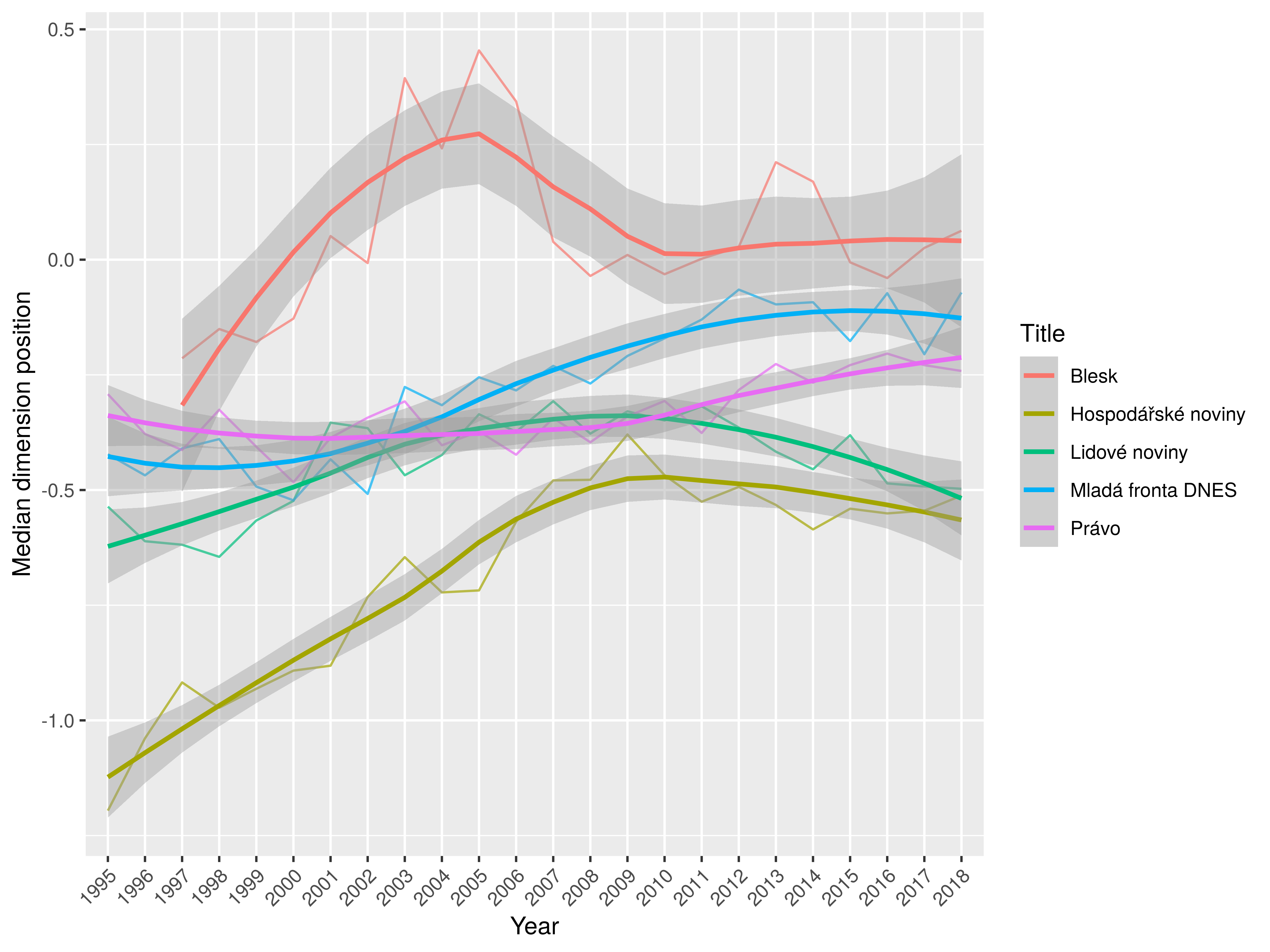
From static/nominal to dynamic/verbal texts
Text typical of HN in 1995:
Koncem ledna tohoto roku předložilo Ministerstvo hospodářství komisi pro malé a střední podnikání hospodářského výboru Parlamentu návrh politiky učňovského školství pro následující období. Na konci února zveřejnily „své“ zásady Unie zaměstnavatelských svazů ČR a Sdružení učňovských zařízení. Případné rozdíly v těchto dvou koncepčních materiálech naznačují, jak odlišné cíle mají jejich autoři. (HN 1995, Dim 1 = -1,16)
Text typical of MfD in 2018:
„Manažerům zjednodušíme práci třeba o pět hodin týdně,“ popisuje šestadvacetiletý Jakub Mynařík svůj projekt Dayswaps, se kterým zvítězil v soutěži začínajících pražských podnikatelů T-Mobile Rozjezdy. Program pomáhá manažerům rychle naplánovat směny pracovníkům. V popisu vašeho projektu se píše, že jde o software, který jediným tlačítkem zohledňuje požadavky zaměstnanců. Co si pod tím mám představit? Z poměrně složitého matematického problému, kterým je pro zaměstnavatele plánování směn, jsme udělali věc jednoho kliknutí. (MfD 21. 5. 2018, ID = mf180521:179, Dim 1 = -0,08)
Dim 2: spontaneous × prepared
…colloquialization, conversationalisation
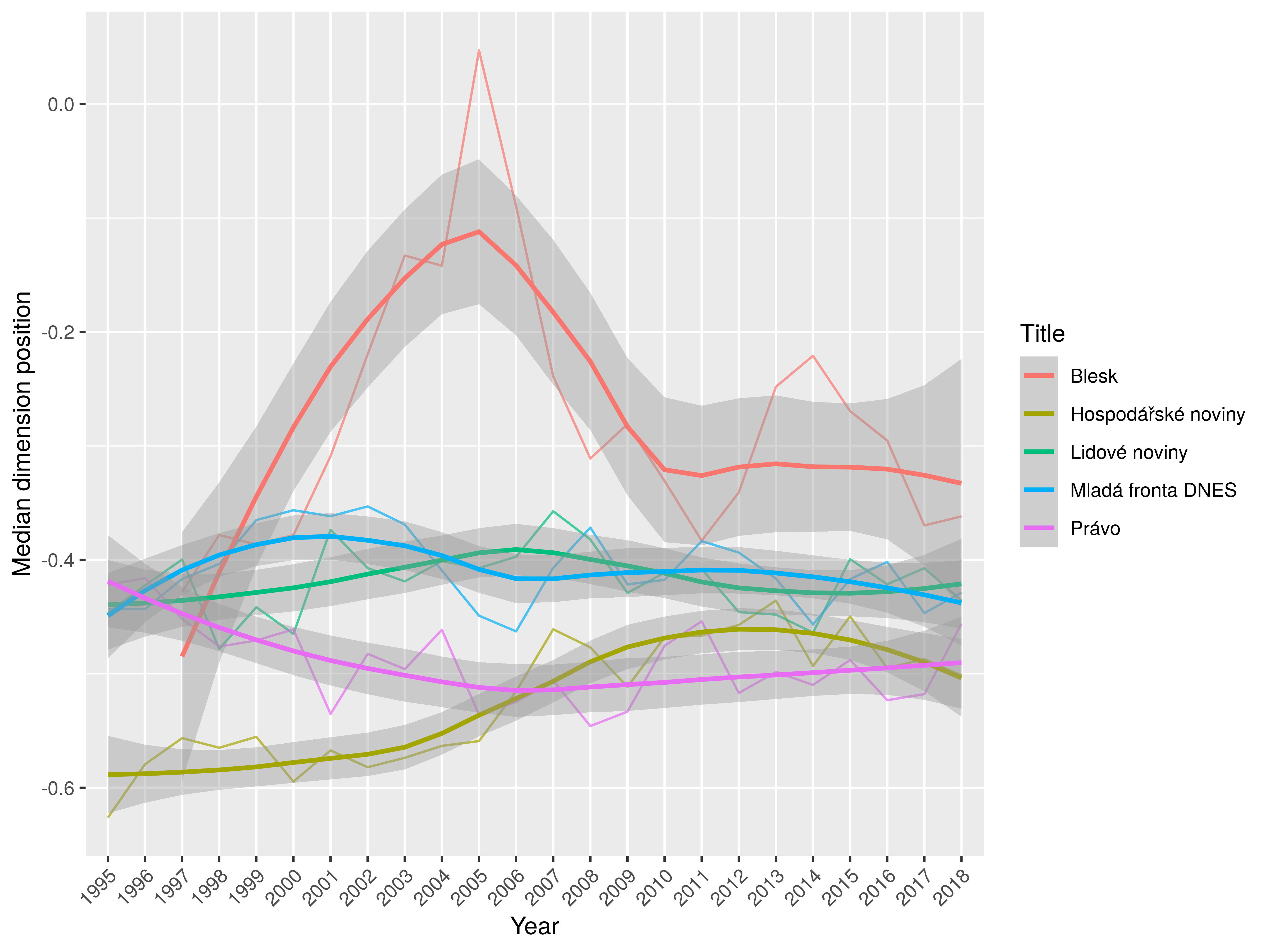
Dim 6: general × particular
the most significant change (w.r.t. the overall variability in dimension)
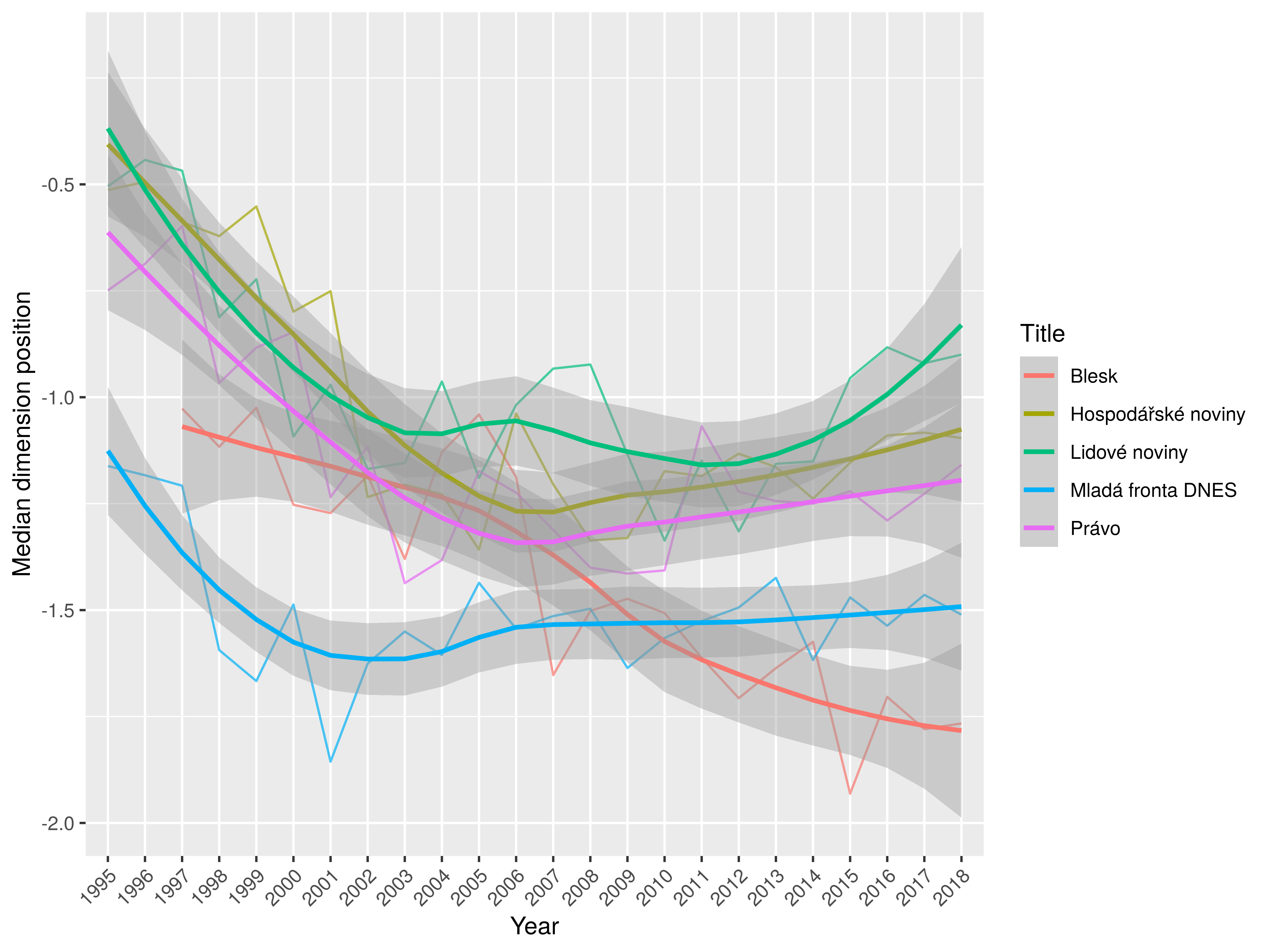
Summary of major tendencies
Significant tendencies: general ➝ particular, higher ➝ lower level of cohesion, explicit attitude ➝ factual
MfD – the most dynamic & prospective and least cohesive within mainstream
HN – significant retreat from static monothematic and retrospective positions
LN – highest level of attitude signalling, high level of cohesion; LN remains retrospective (narration, reporting)
Právo – intermediate in most respects, keeps higher level of cohesion
Blesk – extreme in several dimensions: dynamic, non-cohesive, concrete/particular, least attitudinal
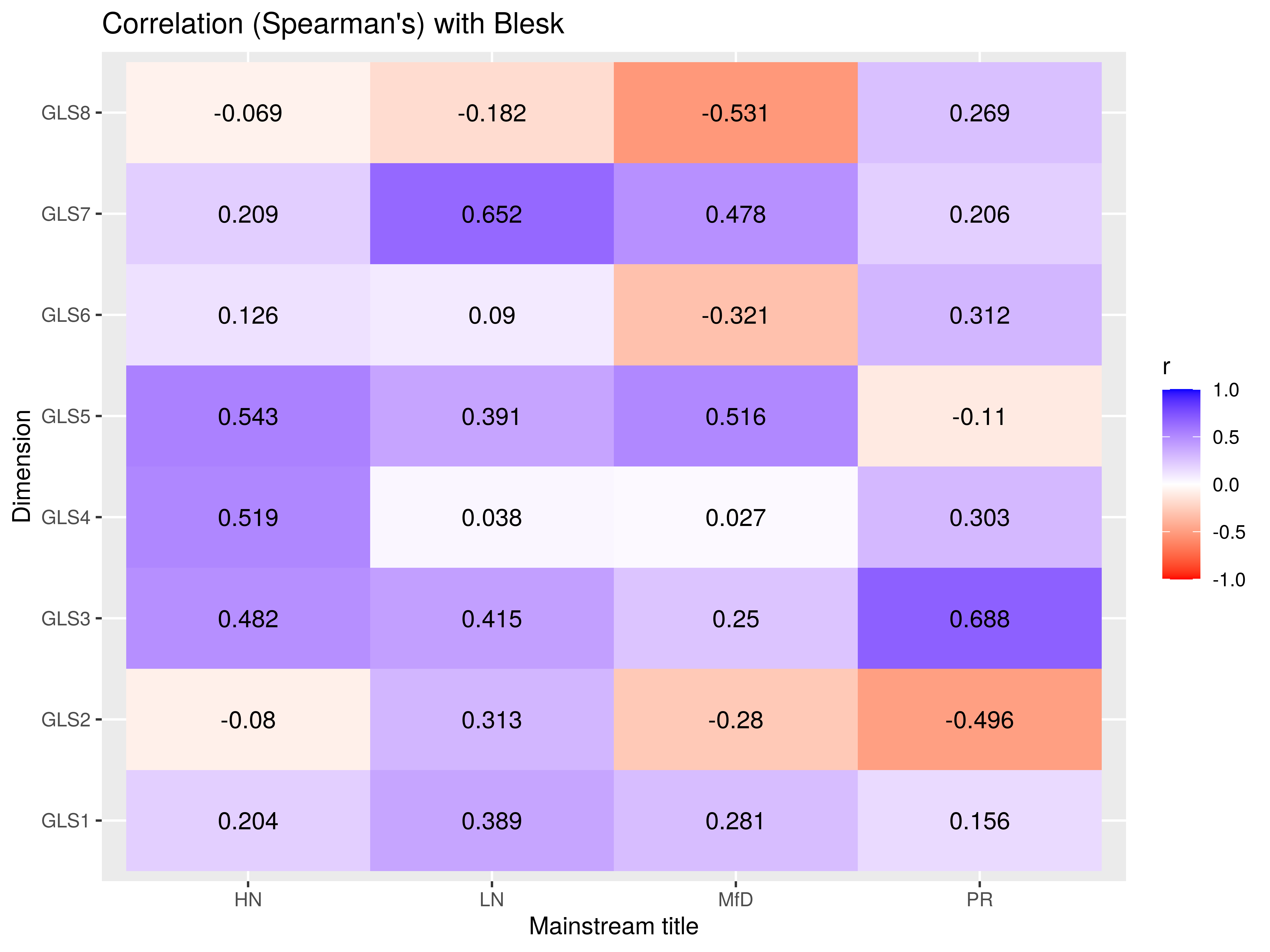
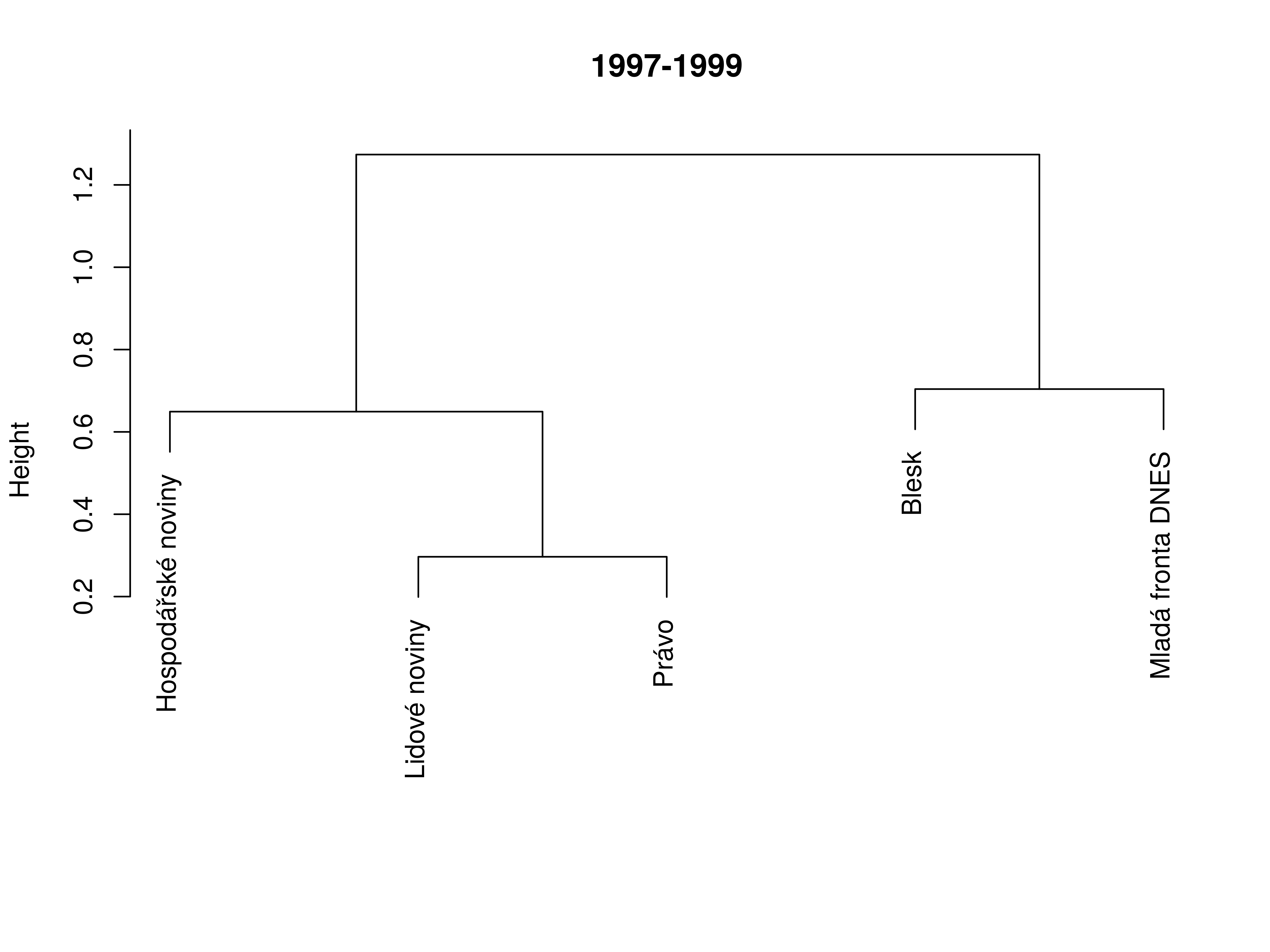
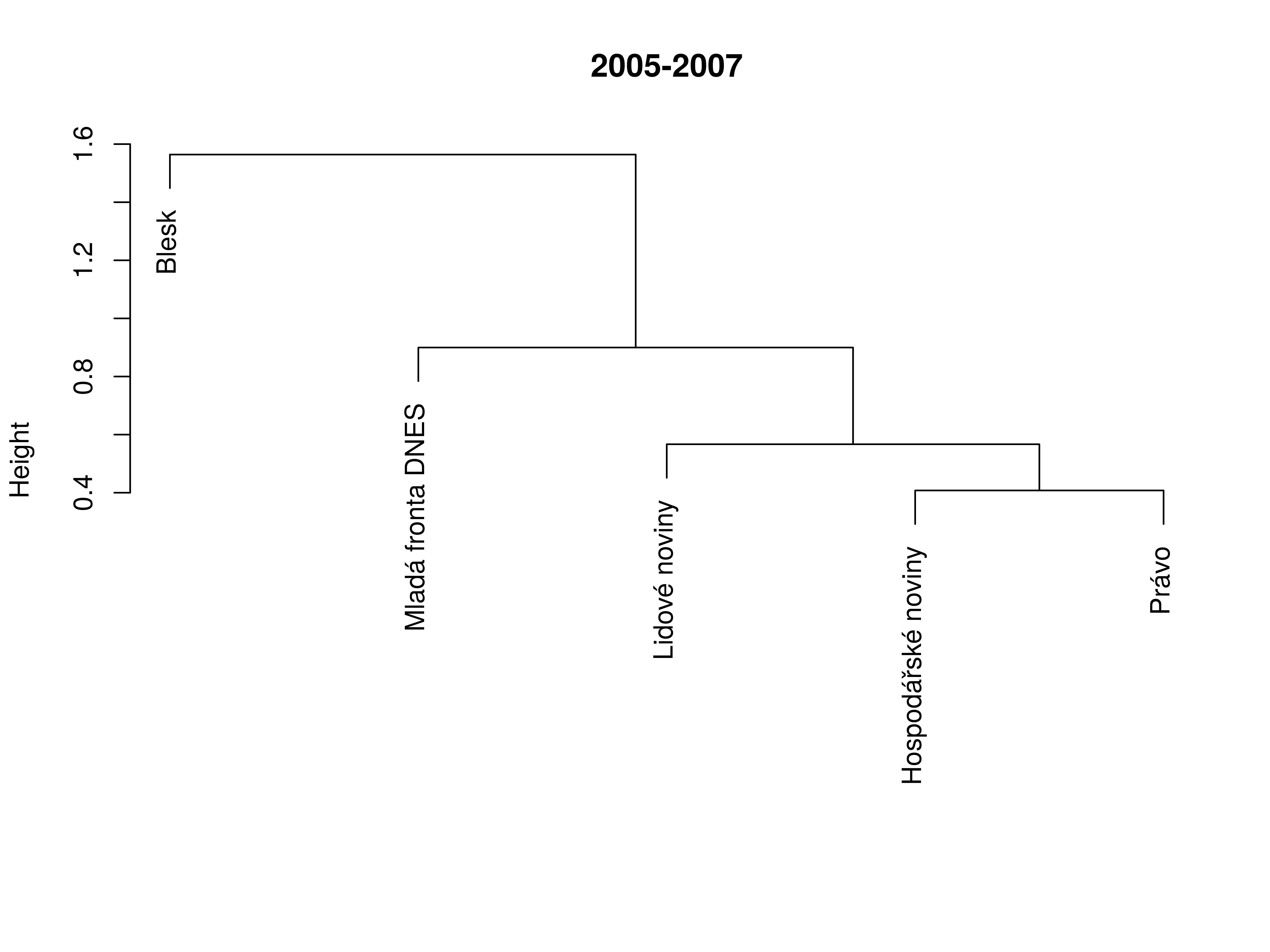
Addendum: tabloidization of mainstream?
Correlation in dimensions
Similarity between titles (1997–1999)
Similarity between titles (2005–2007)
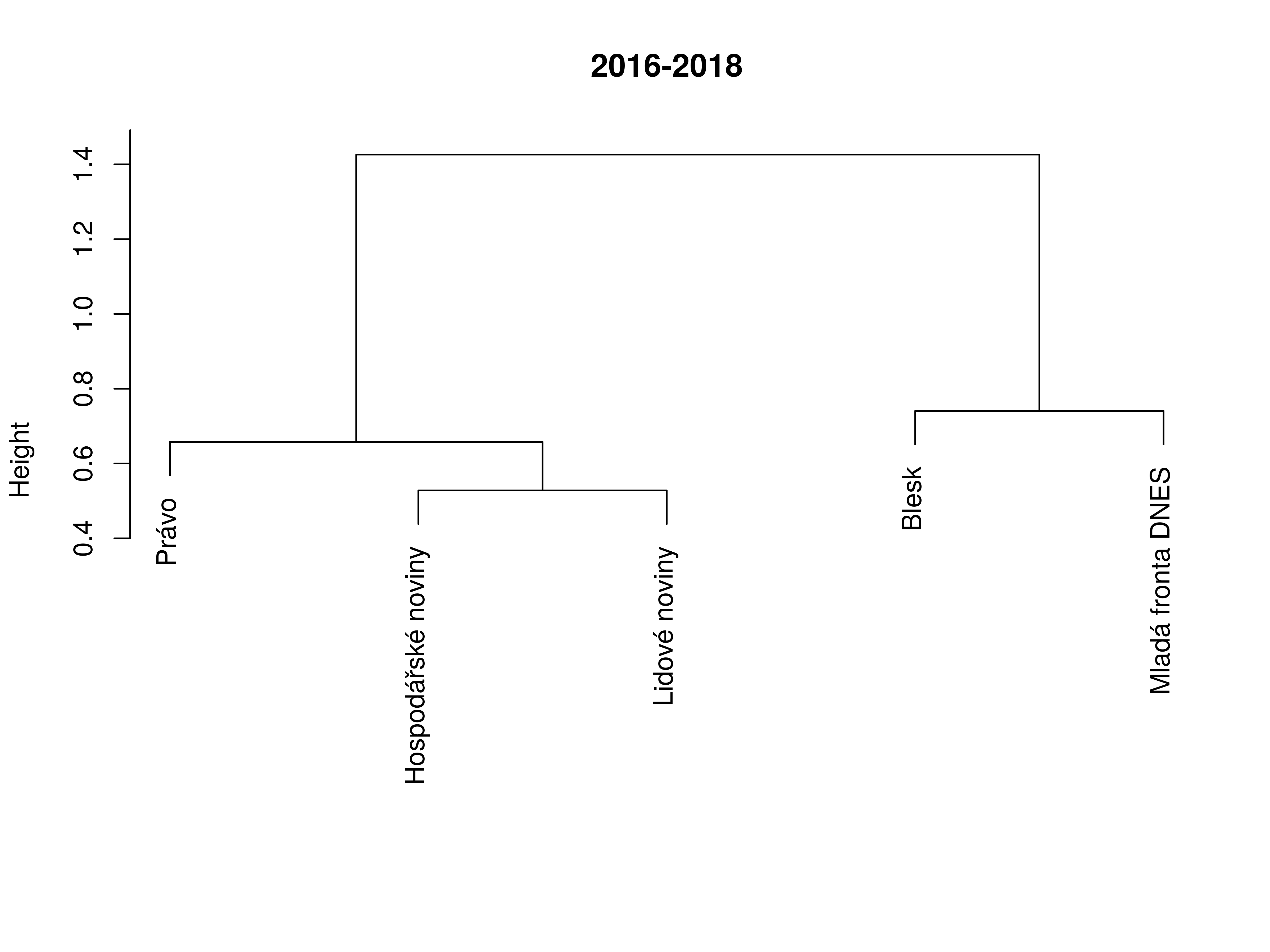
Similarity between titles (2016–2018)
Thank you
References
- Bermel, N. (2014). Czech Diglossia: Dismantling or Dissolution? In J. Arokay, J. Gvozdanovic, & D. Miyajima (Eds.), Divided Languages? Diglossia, Translation and the Rise of Modernity in Japan, China, and the Slavic World (pp. 21–37). Dordrecht: Springer International Publishing.
- Biber, D. (1993). Representativeness in corpus design. Literary and Linguistic Computing, 8(4), 243–257.
- Biber, D. (1995). Dimensions of Register Variation: A Cross-Linguistic Comparison. Cambridge, England: Cambridge University Press.
- Biber, D., & Conrad, S. (2009). Register, Genre, and Style. Cambridge, England: Cambridge University Press.
- Cvrček, V. et al. (2021). From extra- to intratextual characteristics: Charting the space of variation in Czech through MDA. Corpus Linguistics and Linguistic Theory.
- Cvrček, V. - Laubeová, Z. - Lukeš, D. - Poukarová, P. - Řehořková, A. - Zasina, A. J. - Benko, V. (2020): Comparing web-crawled and traditional corpora. Language Resources & Evaluation 54, p. 713–745.
- Čechová, M., Krčmová, M., & Minářová, E. (2008). Současná stylistika. Nakladatelství Lidové noviny.
- Čmejrková, S. (2008). Jazyk médií a jeho konverzacionalizace. Jazykovědné aktuality, 45, 87–100.
- Hoffmannová, J. (2016). Prostěsdělovací styl. In P. Karlík, M. Nekula, & J. Pleskalová, Nový encyklopedický slovník češtiny. Nakladatelství Lidové noviny. https://www.czechency.org
- Hoffmannová, J., Homoláč, J., Chvalovská, E., Jílková, L., Kaderka, P., Mareš, P., & Mrázková, K. (2016). Stylistika mluvené a psané češtiny. Academia.
- Mrázková, K. (2016). Rejstřík. In P. Karlík, M. Nekula, & J. Pleskalová, Nový encyklopedický slovník češtiny (p. 1546–1547). Nakladatelství Lidové noviny. https://www.czechency.org
- Schneiderová, S. (2013). Mediální diskurz. In O. Uličný & S. Schneiderová (Ed.), Komunikační situace a styl. Studie k moderní mluvnici češtiny 2 (p. 95–121). Univerzita Palackého v Olomouci.
Influence of Andrej Babiš on MfD and LN